Latent Feature Space Transformation에 대해 더 자세히 정리하는 두 번째 글이다. 적어도 4개 정도는 더 써야 원하는만큼의 지식을 챙겨갈 수 있지 않을까 싶다. 모르는 개념도 많고.. 어려워서 공부하는데도 꽤 오랜 시간과 노력이 필요할 것 같다.
Latent Feature Space Transformation의 목적은 말 그대로 network를 통해 추출되는 feature들을 사용해서 DA를 하는 것이다. 예를 들어 CNN에서는 여러 개의 convolutional layer를 거쳐 feature map들이 생성될텐데, Latent Feature Space Transformation에서는 DA를 위해서 이 feature map들을 어떻게 해보겠다는 거다. 적절한 feature map 생성을 위해 새로운 loss를 설계하거나, 새로운 학습 방법을 적용해보거나, 아니면 아예 또다른 network를 붙이거나 하는 방식으로 말이다. DA에 더 좋은 feature map을 얻기 위해 진행된 연구들이 LFST 범주에 들어간다보면 될 것 같다.
앞선 글에서도 언급했듯이 Latent Feature Space Transformation는 그림과 같이 3개의 하위 범주를 갖는다.
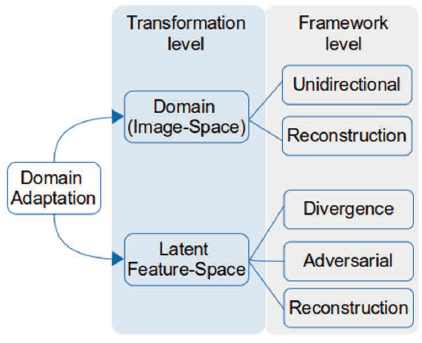
그리고 각 범주의 개념, 목적을 파악할 수 있는 문장을 정리하면 다음과 같다.
- Divergence minimization
A simple approach to learn domain-invariant features and remove distribution-shift is to minimize some divergence criterion between source and target data distributions. - Adversarial training
The goal of the feature network is to learn a latent representation such that the discriminator is unable to identify the input sample domain from the representation. - Cross-domain reconstruction
The reconstruction-based adaptation maximizes the inter-domain similarity by encoding images from each domain to reconstruct images in the other domain.
이번 글에서는 Diveregence minimization 에 대해 조금 더 자세히 알아보도록 하자.
근데 그 전에 광고 한 번 보고 가자ㅎ

A simple approach to learn domain-invariant features and remove distribution-shift is
to minimize some divergence criterion between source and target data distributions.
이 말이 무슨 의미일까? 아니 그 전에 divergence criterion은 뭐지?
찾아보니까 divergence criterion = divergence loss 라고 하더라. 비용 함수를 영어로 표현할 때 보통 loss function이라 하는데, 이외에도 error / cost / objective 그리고 criterion function 으로 표현한다고 한다. (뭐.. 단어 마다 어감의 차이는 있겠지만.. 거기까지는 나도 모르겠다ㅎ)
그래서 저 말을 내가 이해한 내용을 토대로 정리해보면 아래와 같다.
DA를 위해 가장 간단하게 적용해볼 수 있는 방법은 비용 함수로 divergence criterion을 사용하는 것이고, 이를 Divergence minimization이라 부른다.
그럼 divergence criterion이 다른 비용 함수들과는 어떤 차이점을 갖고 있는 걸까?
Input image를 0~1 사이 값으로 매핑하고 이 값으로 비정상 여부를 판단하는 모델에는 주로 cross-entropy가 사용되고, Input image를 feature map으로 매핑하여 이를 데이터 분포로 바라보는 GAN에서는 divergence criterion이 주로 사용된다.
즉, divergence criterion는 데이터 분포를 다룬다. 좀 더 정확히는 두 데이터 분포 사이의 거리(=차이)를 측정하는 데에 사용된다. 근데 사실 divergence criterion는 cross-entropy처럼 딱 하나의 함수가 아니라 하나의 범주다. 두 데이터 분포 사이의 거리를 측정하는 함수들을 총칭하는 단어라는 말이다. 데이터 분포 사이의 거리를 측정하는 방법에는 아래와 같이 여러가지가 있고,
- Kullback - Leibler divergence
- Jensen - Shannon divergence
- Wassertein distance
- Maximum Mean Discrepancy
이 방법들을 논문에서는 퉁쳐서 divergence criterion이란 표현으로 사용한 것 같다.
Divergence minimization는 또.. 4개 하위 방법으로 나뉜다.
- Maximum Mean Discrepancy (MMD)
- Correlation alignment (CORAL)
- Constrastive Domain Discrepancy (CDD)
- Wasserstein distance
다음 글에서는 이 방법들 중 Maximum Mean Discrepancy 와 Wasserstein distance에 대해 정리하도록 하겠다.
[ 참고 사이트 ]
https://blog.lunit.io/2017/04/27/style-transfer/
Style Transfer
Introduction Style transfer란, 두 영상(content image & style image)이 주어졌을 때 그 이미지의 주된 형태는 content image와 유사하게 유지하면서 스타일만 우리가 원하는 style image와 유사하게 바꾸는 것을 말합
blog.lunit.io



