Dice Score와 IoU Score는 Segmentation Task를 진행하면 흔하게 접하게 되는 개념이다. 'Prediction과 Ground-Truth가 얼마나 겹치느냐'를 평가하는 데에 쓰인다. 사실 IoU는 Object Detection에서만 사용되는 개념으로 알고 있었는데 Segmentation에서도 사용된다는 건 이번에 제대로 알게 됐다. 그래서!! 공부한 김에 정리해두고자 한다. 이번 글에서 다룰 내용은 아래와 같다.
- Dice와 IoU의 정의와 차이점
- Score를 Loss로 사용할 때 어떤 차이가 있는지
- 추가로 알아둘 점
1. Dice와 IoU의 정의와 차이점
Dice와 IoU, 더 정확하게는 Dice Score와 IoU Score는 모두 모델이 GT와 얼마나 유사한 결과를 내놓는지를 평가하는데에 쓰이는 Metric이다. 그리고 Metric이기 때문에 모델의 Prediction에 Threshold를 걸어줘서 Binary 형태로 변환한 다음에 GT와 비교하여 계산한다. 정의는 아래와 같다.

Dice Score 수식을 보면 F1-Score와 같다는 걸 알 수 있다. 즉, Dice Score가 1에 가까울 수록 모델의 민감도와 정밀도가 좋다는 뜻이고, 반대로 0에 가까울 수록 민감도 또는 정밀도(둘 중 무엇인지는 실제로 값을 뽑아봐야 알 수 있음)가 안 좋다는 뜻이다.
OK, Dice Score가 뭔지는 알겠어, 그럼 IoU랑 차이점은 뭔데?
수식에서 TP는 'Pred과 GT가 겹친 영역'을 의미하는데 Dice Score는 TP에 x2를 해준 것을 볼 수 있다. IoU 보다 겹친 영역을 더 중요하게 본다는 의미로 받아들이면 된다. 그렇다면 왜 Dice는 TP를 더 중요하게 보는 걸까? Medical Domain으로 넘어와서 생각해보면 쉽게 이해할 수 있다. Medical Domain에서는 Small size lesion은 정말 수두룩하다. 그리고 Lesion size를 정확하게 측정하는 것만큼이나 Lesion location을 찾아내서 의료진에게 가이드 해주는 것도 중요하게 본다. 예시를 극한으로 끌고가서
- Mask image size는 1000x1000인데 Lesion size가 50x50인 케이스가 있다고 가정해보자.
- 그리고 모델이 Lesion locatio은 어느정도 맞췄는데 size를 70x80 정도로 예측했다 가정해보자.
이때 IoU Score를 구하면 모델이 GT 보다 더 크게 잡았다는 이유로 낮은 값이 계산된다. GT보다 더 넓은 Pred으로 인해 분모값이 커지기 때문이다. 반면 Dice Score는 분자가 IoU보다 2배 되면서 분모는 2배 미만으로 커지기 때문에 IoU Score보다 더 높은 성능으로 평가하게 된다. 다시말하면, Dice Score는 IoU Score보다 겹치는 영역을 더 중요하게 생각하는 Metric이라서 모델을 보다 합리적으로 평가한다고 말할 수 있다. (뭐.. Lesion size에 Robust한 Metric이라 생각해도 될 것 같기도 하다)

우리 입장에서는 모델이 이미 작은 병변을 잡아낸 것도 대단한 일인데 GT보다 조금 더 크게 잡았다는 이유로 성능을 낮게 평가하는 건 매우매우 안타까운 일이다. 그래서 TP를 더 중요하게 바라보는 Dice Score를 사용하는 것이라 생각하면 된다.
2. Score를 Loss로 사용할 때 어떤 차이가 있는지
Metric은 살짝 수정하면 Loss function으로도 사용할 수 있다. Dice loss로 알아보자. Dice Score는 1에 가까울 수록 좋은 의미이니까 Loss로 사용하려면 그 반대 의미가 되도록 설정해주면 된다.
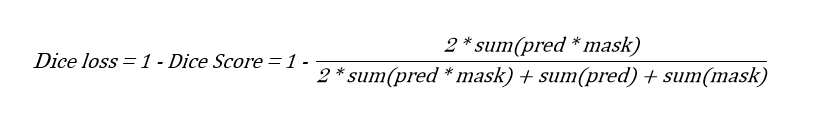
주목할 점은 Score를 구할 때와는 다르게 모델의 prediction을 이진화 과정 없이 바로 사용한다는 점이다. 본래 Deep Learning에서 Loss function은 prediction이 gt와 같아질 수 있도록 Error를 구하는 데에 사용되는 함수이다. 그러기 위해선 prediction이 0~1 사이의 probability(주로 sigmoid 값)로 남아 있어야 0 or 1 값인 gt와 비교하여 error를 계산할 수 있다. Dice loss도 같은 이유로 이진화 과정 없이 사용하는 것이다.
3. 추가로 알아둘 점
Dice loss 식을 보면 dice score term에서 분자에 pred과 mask를 곱한 값을 사용한다. Mask에서 background는 0, foreground는 1로 표현되기 때문에 pred과 mask를 곱하면 결국 mask 상 foreground에 해당되는 값들만 갖고 loss를 계산하게 된다. 그럼 Dice loss는 GT가 0인 부분은 무시해버리고 loss를 구하는 건가??
>> 아니다. 이런 생각은 분자만 놓고 봐서 그런거지 분모도 같이 고려해서 생각해보면 sum(pred)와 sum(mask)가 있기 때문에 GT가 0인 영역에 대해서도 반영하여 loss를 계산한다는 걸 깨달을 수 있다. 그럼에도 Background가 분자에서 무시되는 게 영 찝찝하다면 pred과 mask를 반전시킨 다음 background도 하나의 class로 바라보게 해서 Multi-class segmentation task로 접근하면 된다.
또한 Dice score, IoU score를 구할 때 나는 'per-image=True'로 바라보고 계산하는 편이다. 그니까 이미지 한 장 당 score를 구한 다음 전체를 평균한 값으로 모델의 성능을 평가한다. 다른 영역에서는 모든 이미지를 하나의 이미지로 바라봐서 한 번에 계산할 수도 있겠지만, 의료 영역에서는 주로 '이미지 한 장 = 환자 1명'을 의미하기 때문에 이미지 당 계산한 다음 평균 값을 사용하는 편이다.
< 출처 >
AI Researcher, Moon
https://nurilee.com/2020/01/06/f1-score-%EC%9D%B4%EB%9E%80/
https://ilmonteux.github.io/2019/05/10/segmentation-metrics.html
'Deep Learning > 인공지능 개념 정리' 카테고리의 다른 글
| Probability Calibration 개념 정리 (0) | 2021.12.16 |
|---|---|
| 0 ~ 255의 픽셀 값을 왜 0 ~ 1로 rescale하는 걸까? (1) | 2021.09.03 |
| IoU, Intersection over Union 개념을 이해하자 (12) | 2021.08.31 |
| CNN에서 커널 사이즈는 왜 3x3을 주로 쓸까? (0) | 2020.01.15 |
| CNN이 이미지에 더 효율적인 이유 (0) | 2020.01.14 |


