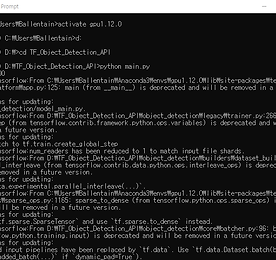
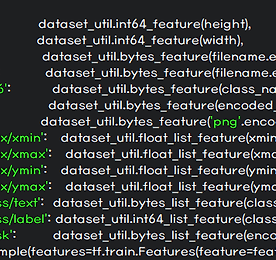
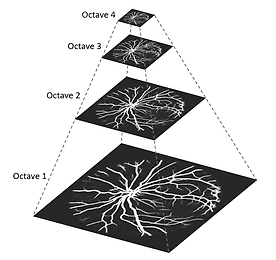
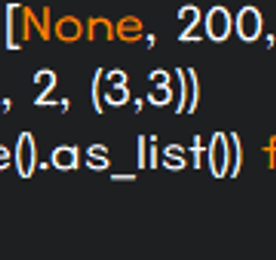
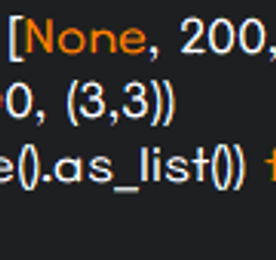
분류 전체보기 썸네일형 리스트형 homography matrix 다루기 / cv2.findHomography( ), cv2.warpPerspective( ) 제목을 뭐로 해야할지 몰라서 homography matrix 다루기라 두루뭉실하게 적어놨다. 오늘은 아래의 그림과 목차 흐름으로 정리하고자 한다. cv2.xfeatures2d.SIFT_create( ) 함수로 keypoint와 descriptor 추출 cv2.BFMatcher( ) 함수로 keypoint 매칭 cv2.findHomography( ) 함수로 homography matrix, H 추출 추출한 H로 이미지 변환 → cv2.warpPerspective( ) 함수 사용하면 쉽게 할 수 있는데, 이번 글에서는 H를 직접 다루는 방법으로 정리하고자 한다. 정합 결과 확인 먼저 말해두자면, 난 SIFT 이론에 대해 아직은 정확히 모른다. -> 20.01.15 논문 쓰려고 공부했다. 이해한 데까지 정리도.. 더보기 2.2. Mask R-CNN을 Retrain 시켜보자 create_tf_record.py를 통해 TFRecord 파일을 만들었으니 이제 Retrain 하는 방법에 대해 알아볼 차례다. Retrain 방법에 대해 구글링해본 사람이라면 한 번쯤은 이런 생각을 해본 적 있지 않을까 싶다. (뭐.. 나만 삐뚫어진 걸 수도 있지만..ㅎㅎ) '뭐야, 이게 무슨 API야? 사용성이 너무 떨어지는데?' 그래서 기존에 알려진 방식보다 더 사용성을 높여 보려고 이것 저것 추가해서 작성해봤다. 순서는 다음과 같다.[pretrained_model 폴더]에 mask_rcnn_resnet101_coco_2018_01_28 모델 다운로드 모델은 detection_model_zoo에서 다운받으면 된다. [model_configs 폴더] 생성 후 ./object_detection/sam.. 더보기 2.1. Custom Dataset으로 TFRecord 파일 만들기 Tensorflow Object Detection API를 사용해서 모델 재학습을 하려면 TFRecord 형태의 input data를 만들어줘야 한다. TFRecord는 "Tensorflow 전용 학습 데이터 저장 형태" 정도로 알아두면 될 것 같다. 제대로 알아보지는 않았지만 Tensorflow로 설계한 모델 학습에 TFRecord를 사용하면 학습 속도가 개선되는 장점이 있다고 한다. 자세하게 알고 싶다면 여기1와 여기2에 들어가서 관련 설명을 읽어보면 될 것 같다. 그리고 이미지를 byte 단위로 읽고 쓰는 법에 대해 모르는 경우라면, [Python] - 이미지 읽는 방법 / cv.imdecode( ), io.BytesIO( ) 을 읽으면 도움이 될 거다. 이제 본격적으로 Custom Dataset을.. 더보기 이미지 읽는 방법 / cv.imdecode( ), io.BytesIO( ) 이미지를 읽는 방법에는 여러가지가 있다. OpenCV를 사용해서 읽는 방법도 있고, PIL를 이용해서 읽는 방법도 있다. 그리고 최근에는 이미지 파일을 Binary 형태로 읽은 다음 ( = byte 단위로 읽는다는 의미 ) jpg로 decoding하는 방법도 있다는 걸 알게 됐다. 하나씩 그 사용법에 대해 정리해보도록 하자. 1. cv2.imread( ) import cv2 path = './test_image.jpg' img = cv2.imread(path) 내가 주로 사용하는 함수다. 2. PIL.Image.open( ) from PIL import Image path = './test_image.jpg' img = Image.open(path) 가끔 코드 검색을 하다 보면 접하게 되는 함수다. 직.. 더보기 2. Tensorflow Object Detection Model Retrain 방법에 대해 알아보자 진행하는 논문만 마무리하고 다시 쓰고자 계획했는데 어느덧 반년이 넘는 시간이 흘러버렸다.. 지금은 논문 작업이 거의 완료돼서 시간적 여유가 많으니 Tensorflow Object Detection Model Retrain 방법에 대해 정리하도록 하겠다. Retrain에는 segmentation도 같이 진행하는 Mask R-CNN 모델을 사용했다. Dataset은 여기에서 Training Data에서 Rigid Instruments만을 받아 학습에 사용했다. Rigid Instruments를 받아보면 4개의 폴더가 있는데 그 중 3개는 학습용으로, 나머지 1개는 검증용으로 정리해서 사용했다. 정리된 Dataset와 사용한 코드들은 내 Github에서 다운받을 수 있다. 이제 다음 글에서 다운받은 Custo.. 더보기 SIFT 알고리즘 Scale Invariant Feature Transform (SIFT) 개발하기 급급해서 OpenCV 함수로만 사용해왔는데 논문을 쓰는 입장이 되어보니 원리에 대해 공부해야할 필요성이 생겨버렸다. 그래서 내가 할 수 있는 최대로 구글링해서 공부했고 그 내용들을 정리해두려고 한다. 시간이 지나면 일부분은 까먹게 될테니깐..! SIFT Algorithm 이미지의 Scale (크기) 및 Rotation (회전)에 Robust한 (= 영향을 받지 않는) 특징점을 추출하는 알고리즘이다. 이미지 유사도 평가나 이미지 정합에 활용할 수 있는 좋은 알고리즘이다. 논문에서는 4단계로 구성되어 있다고 밝히고 있다. Scale-space extrema detection Keypoint localication Orienta.. 더보기 CNN에서 커널 사이즈는 왜 3x3을 주로 쓸까? 대부분이 3x3 kernel size를 사용한다. 5x5도 있고 7x7도 있고 다양하게 사용할 수 있는데 대부분이 3x3을 쓴다. 이유는 모델 파라미터 수에서 큰 차이가 있기 때문이다. (1) 3x3 kernel (2) 5x5 kernel 3x3 kernel 2개를 사용하는 것이 5x5 kernel 1개를 사용하는 것보다 모델 파라미터 수가 더 적다. 그래서 3x3을 주로 사용하는 것이다. 더보기 CNN이 이미지에 더 효율적인 이유 이미지를 다루데에는 CNN을 가장 많이 사용한다. convolution이 이미지 연산에 특화되어 있기 때문이다. 근데 왜 특화 되어 있다 말할 수 있는 걸까? convolution layer와 fully connected layer를 비교해보면 이에 대한 답을 찾을 수 있다. 훨씬 적은 모델 파라미터 요구 개수 입력 이미지 크기가 [ 200 x 200 ]라고 가정했을 때 (1) fully connected layer의 경우 node를 1개로만 둬도 40,001개(가중치 40,000 + 바이어스 1)의 모델 파라미터가 필요하지만 (2) convolution layer를 사용하는 경우 3x3 커널 100개를 사용한다해도 1,000개(커널 900 + 바이어스 100)만 필요하다. 결과적으로 cnn연산이 훨씬 .. 더보기 이전 1 ··· 5 6 7 8 9 10 11 다음