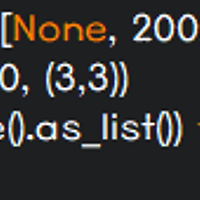
supervised learning에서는 모델 구조 설계 못지않게 loss function을 정의하는 것이 중요하다.
대표적인 loss function은 다음과 같다.
- tf.reduce_mean(tf.square(pred - true)) → regression
- tf.nn.sigmoid_cross_entropy_with_logits( ) → binary classification과 multi-label classification
- tf.nn.softmax_cross_entropy_with_logits_v2( ) → multi-class classification
해결하고자 하는 문제에 맞게 loss function을 설정해 사용해주면 된다.
딥러닝 공부 시작할때만 해도 위의 3개 loss function만 알고있으면 문제없었지만,
공부를 하다보니
joint training과 alternate training에 대해 새롭게 알게되어 정리하고자 한다.
1개의 model에서 n개의 output을 출력한다면 이에 맞춰 n개의 서로 다른 loss를 뽑아낼 수 있다.
여기서 joint training과 alternate training 방식으로 나뉘게 된다.
여러개의 loss들을 어떻게 처리하느냐에 따라 갈리는 것이다.
joint training
여러 개의 loss들을 하나의 값으로 더해서 최종 loss로 사용하는 훈련 방식 이다.
YOLO v1 model을 대표적 예로 들 수 있다.
YOLO는 마지막 층의 output을 channel 단위로 잘라서 서로 다른 역할을 부여한 구조다.

output layer의 출력 7x7x30에서
5개 채널은 첫번째 bbox에 대한 정보(x, y, w, h, confidence score),
5개 채널은 두번째 bbox에 대한 정보, 나머지 20개는 class score로 사용한다.
각 채널이 서로 다른 역할을 수행하게 하려면 이에 맞게 loss function을 정의해줘야하기 때문에
YOLO 에서는 정의되어야할 loss function도 여러 개가 된다.
결과적으로 YOLO는 총 다섯개의 loss function을 통해 최종 loss 값을 계산한다.

자세한 설명은 여기서는 생략하겠고 핵심은
total loss = loss1 + loss2 + loss3 + loss4 + loss5 란 것이다.
joint training은 여러 개의 loss들을 더해서 모든 task들을 한 번에 학습하는 방식이다.
alternate training
loss 개수에 맞게 optimizer를 생성해 각 optimizer를 번갈아 가면서 학습하는 방식이다.

이런 식으로 shared layer를 기반으로 n개의 task를 수행하는 모델이 있다고 가정하자. ( YOLO도 이 경우에 해당하긴 한다)
한 개의 이미지를 보고 Task A는 색을 분류하고, Task B는 옷 종류를 분류하는 모델을 예로 들 수 있겠다.
1 2 3 4 5 6 7 8 9 10 11 12 | type_loss = tf.nn.softmax_cross_entropy_with_logits_v2(type_pred, type_true) color_loss = tf.nn.softmax_cross_entropy_with_logits_v2(color_pred, color_true) type_optimizer = tf.train.AdamOptimizer().minimize(type_loss) color_optimizer = tf.train.AdamOptimizer().minimize(color_loss) data_generator = load_imaged() sess = tf.Session() sess.run(tf.global_variables_initializer()) for epoch in range(epochs): batch_x, batch_y = next(data_generator) sess.run([type_optimizer, color_optimizer], feed_dict = {input_tensor : batch_x, y : batch_y}) | cs |
이런 식으로 task 개수에 맞게 loss function과 optimizer를 생성한 뒤,
sess.run( )을 통해 두 optimizer를 실행시켜주면 된다.
joint training과 alternate training 중 어느 것이 더 좋은 학습 방법인지,
어떤 경우에 joint 또는 alternate를 쓰는 게 효율적인지에 대해 가이드(?) 해주는 글을 아직 찾지 못했다.
어쩌다 발견하게 되면 추가로 작성하도록 하자.
※ multi task training 이란 용어도 있는데, joint training과 alternate training을 아우르는 개념이 아닐까 생각된다.
[ 참고 사이트 ]
https://jg8610.github.io/Multi-Task/
https://medium.com/@kajalgupta/multi-task-learning-with-deep-neural-networks-7544f8b7b4e3
https://curt-park.github.io/2017-03-26/yolo/
https://blog.naver.com/sogangori/220993971883
https://www.pyimagesearch.com/2018/06/04/keras-multiple-outputs-and-multiple-losses/
'Deep Learning > 인공지능 개념 정리' 카테고리의 다른 글
| CNN에서 커널 사이즈는 왜 3x3을 주로 쓸까? (0) | 2020.01.15 |
|---|---|
| CNN이 이미지에 더 효율적인 이유 (0) | 2020.01.14 |
| Protocol Buffer 실습 2 (0) | 2019.07.02 |
| Protocol Buffer 실습 1 (0) | 2019.07.02 |
| Protocol Buffer 개념 (0) | 2019.07.02 |