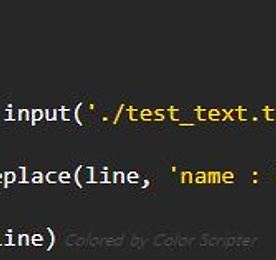
전체 글 썸네일형 리스트형 Python의 fileinput module로 파일 수정하는 방법 fileinput 모듈이라고 해서 크게 다른 건 없는 것 같다. 그냥 Python에서 파일 입출력할 때 쓰는 모듈인데 흔히 쓰는 open( ) 함수 말고 fileinput.input( ) 함수를 쓰는 거라 생각하면 된다. 그럼 왜 fileinput 이란 모듈을 따로 만들었으며 언제 사용하는 걸까?? 이렇게 저렇게 쓰다보니 fileinput을 사용하면 보다 간단하게 파일 수정을 할 수 있기 때문이란 생각을 하게 됐다. 아래와 같이 test_text.txt 파일이 있다고 가정하자. name : tube name : ryan name : apeach 그리고 형태는 유지시키면서 두 번째 줄의 "ryan"을 "라이언"으로 바꿔보도록 하자. open( )을 사용하면 불가능한 건 아니지만 fileinput.input.. 더보기 imgaug 라이브러리 사용 방법 classification이나 segmentation 작업을 위해 image augmentation을 하는 것은 그리 어려운 일이 아니다. 근데 object detection 영역으로 넘어오면 얘기가 달라진다. train image에 대해 augmentation을 진행할 때 ground truth도 같이 진행해줘야 하는데 이 과정이 까다롭기 때문이다. 예전에 잠깐 공부할 때는 flip, rotate, shift 등을 하나하나 직접 짜서 augmentation을 진행했었는데.. 우연히 회사 옆자리 연구원으로부터 imgaug 라이브러리를 알게되어 사용 방법을 정리하고자 한다. imgaug ? Image Augmentation을 위한 라이브러리다. 이곳에서 지원 augmentation 방법들을 확인할 수 있다.. 더보기 Python으로 지정 경로에 폴더 존재하는지 확인하고 없으면 폴더 생성하는 방법 간혹가다가 경로 설정을 해주면 해당 경로에 폴더가 존재하지 않는다는 에러를 만나게 된다. 이런 에러를 잡아주기 위한 코드라 할 수 있겠다. 핵심은 os.makedirs( ) 함수이데, 지정한 경로의 상위 경로마저 없는 경우 그것까지 만들어준다. import os def makedirs(path): try: os.makedirs(path) except OSError: if not os.path.isdir(path): raise 더보기 Anaconda, Python, CMD, 명령어 정리 1. 가상환경 생성 >>> conda create --name 원하는이름 python=원하는버전 (ex) conda create --name gpu1.12.0 python=3.6.5 2. 가상환경 리스트 확인 >>> conda info --envs 3. 가상환경 활성화 >>> conda activate 가상환경이름 (ex) conda activate gpu1.12.0 4. 모듈 다운로드 >>> conda install 모듈이름 (ex) conda install tensorflow-gpu=1.12.0 5. Dependencies 없이 원하는 모듈만 다운로드 >>> conda install --no-deps 모듈이름 or pip install --no-deps 모듈이름 (ex) conda install --.. 더보기 Python file 우클릭 시 context menu에 Anaconda 가상환경 idle 뜨게 하는 방법 파이썬을 설치하면 기본적으로 파이썬 파일 우클릭 시 context menu에 [ Edit with IDLE ] 이 생겨 바로 열어줄 수 있다. 근데 이게 아나콘다 가상환경을 사용하는 경우에는 안 뜨더라. 그래서 위 사진처럼 [ Edit with ENV -> Edit with GPU1.12.0 ] 을 통해 열어줄 수 있는 방법이 있나 하고 찾아봤다. 설정 방법은 다음과 같다. 실행 창에 regedit 입력 후 레지스트리 편집기를 띄운다. 컴퓨터\HKEY_CLASSES_ROOT\Python.File 을 찾는다. 기존에 있는 editwithidle / editwithidle\shell / editwithidle\shell\edit36 / editwithidle\shell\edit36\command 와 똑같이 .. 더보기 Python으로 시스템 변수 추가하는 방법 Code 1 2 import sys sys.path.append('C:/Users/Ballentain/Desktop/test') cs 설명 시스템 변수에 경로를 추가하면 무엇이 좋냐고 물어본다면, 파일을 import할 때 경로 신경 안 쓰고 바로 import해줄 수 있어서 좋다고 답할 수 있을 것 같다. 말로는 이해가 힘들다. 예제를 통해 살펴보자. test 폴더에는 train.py 와 obj 폴더가 들어있고, obj 폴더에는 trainer.py가 들어있다. [ train.py ]는 obj의 trainer.py를 import하게끔만 설정해 놨고, [ trainer.py ]는 실행 Hi 를 출력하도록 설정해놨다. 위와 같은 구조 아래에서 train.py를 실행하면 trainer.py가 import 되어 에.. 더보기 (1) Advancing Medical Imaging Informatics by Deep Learning-Based Domain Adaptation 정리 시작 Medical Image Dataset에서는 환자 케이스, 촬영 장비, 촬영 방식 등과 같은 다양한 요인에 의해 distribution-shift (also known as domain-shift) 현상이 발생한다. 그리고 이 domain-shift 현상이 모델의 성능을 꽤 많이 떨궈서 성능 문제로 이어지게 된다. Hospital A에서 수집된 데이터셋으로 개발된 모델이 AUC 0.99를 찍었다 하더라도, Hospital B 데이터셋에서는 AUC 0.7도 안 나오는 현상이 발생한다. Domain-shift 현상 때문이다. 당연하게도 이 문제점을 해결하기 위해 많은 연구들이 진행되었고, "Domain Generalization (DG)" 또는 "Domain Adaptation (DA)"의 키워드로 검색하면.. 더보기 선형 보간법과 쌍선형 보간법 다양한 Conv 연산 방법들 중 하나인 Deformable Conv에 대해 공부하기 위해 [논문] Deformable Convolutional Networks을 읽던 중, 쌍선형 보간법(Bilinear Interpolation)이라는 처음 보는 개념을 접하게 됐다. 보간법, 선형 보간법은 들어봤는데 쌍선형 보간법은 뭘까? 그래서 이 놈은 무엇인지 구글링하면서 공부 좀 해봤고, 그 과정에서 깨달은 내용들을 수식과 코드 위주로 정리해놓고자 한다. 보간법 ? 이미 알려진 값들을 활용하여 원하는 위치에서의 값을 추정하는 방법의 한 종류이다. 보간법, 선형 보간법, 쌍선형 보간법에 대한 더 자세한 정의는 여기에서 참고하길 바란다. 1. 선형 보간법 우리는 이미 알고 있는 x1, y1, x2, y2, a 값을 활용.. 더보기 이전 1 ··· 4 5 6 7 8 9 10 11 다음