 Tensorflow 개념 정리) 텐서, 변수, 오퍼레이션, 계산 그래프
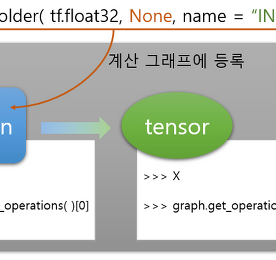
MNIST 분류 문제를 공부할 때만 해도 사용법 익히기에 급급했기 때문에 tensorflow를 제대로 이해하고 다루진 않았었다. 일반적인 파이썬 코드 구현하고는 다르게 tensorflow는 계산 그래프에 노드( = 연산, 계산, 오퍼레이션 )을 추가하고 session을 통해 실행해줘야 하는 구조라고만 이해하고 넘겼다. tf.placeholder( ), tf.layers.conv2d( ), tf.train.AdamOptimizer( )와 같은 함수들로 계산 그래프를 그려가며 모델을 설계하고, tf.Session( ).run( )으로 그려진 계산 그래프를( = 설계된 모델을 ) 실제로 실행하는 구조라고만 이해했었다. + X = tf.placeholder( tf.float32, None) 의 경우, X는 tf..
더보기
Tensorflow 개념 정리) 텐서, 변수, 오퍼레이션, 계산 그래프
MNIST 분류 문제를 공부할 때만 해도 사용법 익히기에 급급했기 때문에 tensorflow를 제대로 이해하고 다루진 않았었다. 일반적인 파이썬 코드 구현하고는 다르게 tensorflow는 계산 그래프에 노드( = 연산, 계산, 오퍼레이션 )을 추가하고 session을 통해 실행해줘야 하는 구조라고만 이해하고 넘겼다. tf.placeholder( ), tf.layers.conv2d( ), tf.train.AdamOptimizer( )와 같은 함수들로 계산 그래프를 그려가며 모델을 설계하고, tf.Session( ).run( )으로 그려진 계산 그래프를( = 설계된 모델을 ) 실제로 실행하는 구조라고만 이해했었다. + X = tf.placeholder( tf.float32, None) 의 경우, X는 tf..
더보기






