Domain Adaptation의 한 부류인 Latent Feature Space Transformatioon에 대한 네 번째 정리 글이다. 두 번째, 세 번째 글에서는 Divergence minimization에 대해 다뤘었고, 이번 글에서는 Adversarial training에 대해 정리하려고 한다. 논문에서는 Adversarial training에 대해 6 문장 정도만 할당해서 간략하게 언급하고 있는데 그 내용을 정리해보면 아래와 같다.
- DA를 위해 GAN의 경쟁적 학습 개념을 적용한 방법이다.
- generator와 discriminator를 경쟁적으로 학습시킨다.
- discriminator가 input image의 domain이 source인지 target인지를 구분 못하도록 generator를 학습시키는 것을 목표로 한다.
- 여기서 discriminator는 domain discriminator라 부른다.
- Chest X-ray를 사용한 논문에 대해서는 따로 소개하지 않았다.
나만 불만족스러운 걸까? 아무리 리뷰 논문이라지만... 정확하게 이해하기에는 설명이 없어도 너~~무 없다. DA라 하면.. Robust Classifier를 학습시키는 게 목적인데 discriminator가 왜 나오는 건데? 이게 DA랑 무슨 상관이지? domain이 source인지 target인지 알아내서 뭘 어쩌겠다는 거야?
이 궁금증들을 해결하기 위해 "adversarial training이란 domain adaptation"을 키워드로 구글링해보니까 정리 잘 된 블로그들이 많이 뜨더라. 하나 하나 읽어가며 이해한 내용들을 기존 블로그들이랑은 다른 관점으로 정리해보고자 한다. 고로, 이 글은 여기서부터가 진짜라고 보면 된다.
"Domain-Adversarial training of Neural Networks, DANN"
여러 블로그들이 공통적으로 리뷰한 논문이다.
2015년에 나온 논문인데 2021.09.29. 기준 인용수가 3669회이니.. 이 분야에서 고전급 논문이라 보면 될 것 같다.
Source Dataset에서 성능이 잘 나오는 Classifier라고 해서 Target Dataset에서도 성능이 잘 나온다고 보장할 수 없다. Domain-shift가 발생하기 때문이다. 이 논문에서는 Domain-shift 현상을 해결하기 위해 GAN의 경쟁적 학습 개념을 적용한다. 이를 위해 일단 네트워크를 일반적인 Classifier와는 다르게 아래와 같이 총 3개로 분리해서 설계한다.
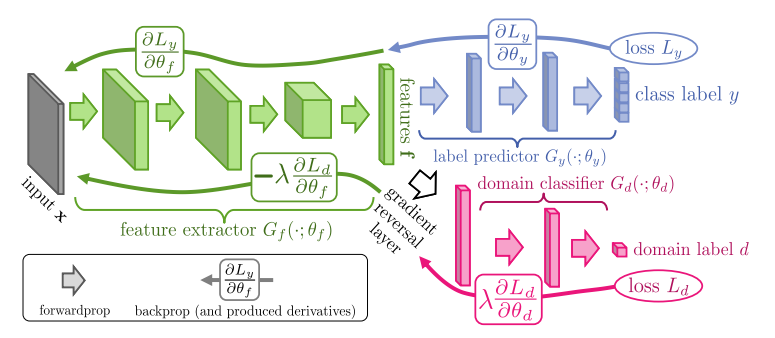
feature extractor가 label predictor의 성능은 높이면서도 domain classifier의 성능은 낮출 수 있는 feature를 뽑도록 학습시키는 게 해당 논문의 가장 중요한 컨셉이다. 바꿔말하면 domain에 대한 정보는 뭉개면서도 source label에 대한 정보는 살리도록 feature extractor를 학습시키겠다는 말이다. feature extractor와 domain classifier를 서로 경쟁적으로 학습시키면 이게 가능해진다.
feature extractor와 domain classifier를 경쟁적으로 학습시킨다는 말이 처음엔 헷갈릴 수 있다. DANN이 전형적인 GAN 구조로 설계되어 있는 것도 아니고 label predictor도 존재하는 구조이기 때문이다. GAN이랑 DANN이랑 비교해보면서 이해해보도록 하자. 그림에서는 feature extractor = generator / domain classifier = domain discriminator / label predictor = task classifier 로 표현했다.
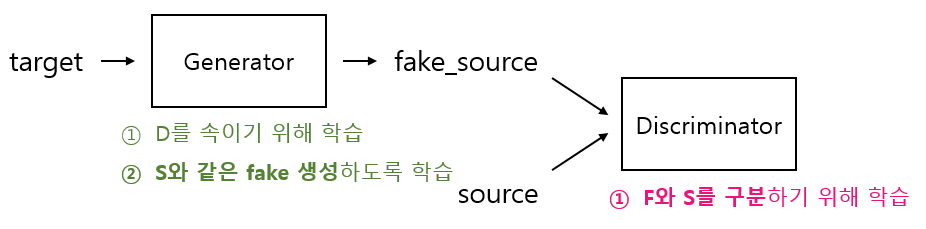
먼저 헷갈리게 하는 task classifier는 없애고 generator와 discriminator만으로 구성하여 전형적인 GAN처럼 학습시킨다고 가정해보자. 그럼 아래 그림과 같이 generator는 discriminator를 속이기 위해 학습되고, discriminator는 fake와 real를 판별하기 위해 학습된다. 이 구조 속에서는 초점이 generator가 target을 이용하여 얼마나 source 같은 fake_source를 생성하느냐로 맞춰지게 된다. discriminator를 generator의 좋은 생성 능력을 위한 보조 모델로만 역할을 한다.
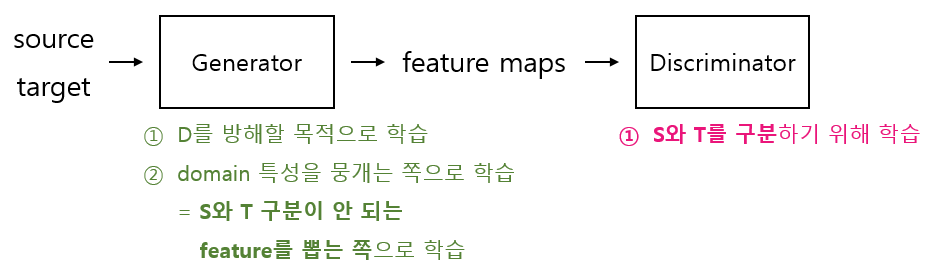
반면 DANN은 GAN과는 초점을 달리 한다. generator가 source domain과 target domain의 특성을 얼마나 잘 뭉갤 수 있는지가 일차적인 초점이 된다. 이를 위해 DANN에서는 아래 그림처럼 source를 discriminator가 아닌 generator에 넣어준다. 그리고 (1) generator는 source domain과 target domain 구분에 아무 도움이 안 되는 feature를 뽑도록 학습시키고, (2) discriminator는 뭉개진 feature라 하더라도 이를 분석해서 source domain인지 target domain인지 판별하도록 서로 경쟁시키면서 학습시킨다.
지금까지 설명이 이해됐다면 이제 task classifier도 추가해서 생각해 보도록 하자. 근데 그 전에 광고 한 번 보고 오자.

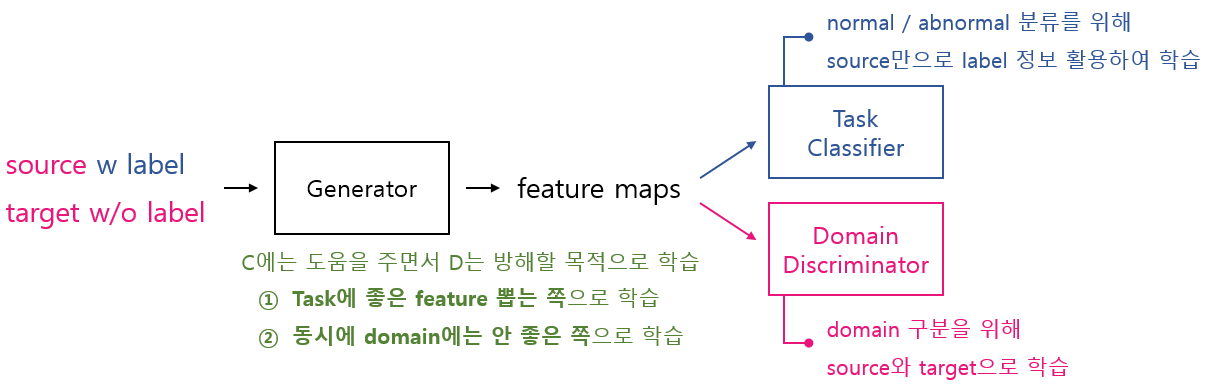
task classifier까지 추가된 온전한 DANN은 "task classifier에는 좋으면서도 domain discriminator에는 안 좋은 feature maps을 뽑아내는 generator 학습"에 초점을 둔다. 애초에 DANN은 target domain에서도 성능 높은 모델을 얻는 것이 목표이고, 이를 위해 domain discriminator를 추가해서 adversarial training을 시키는 구조이기 때문이다. 아래 그림은 DANN의 전체적인 학습 흐름을 나타낸다. task classification을 위한 데이터와 domain discrimination을 위한 데이터를 동시에 generator에 넣어서 각각의 목적에 맞게 학습을 진행하는 흐름이라는 것을 확인할 수 있다.
지금까지 Advancing medical Imaging Informatics by Deep Learning-Based Domain Adaptation 논문 리뷰를 위해 Domain-Adversarial training of Neural Networks 논문에 대해 알아보았다. 글과 그림을 통한 설명만으로는 전달할 수 있는 범위에 한계가 있는 것 같다. 이렇게 끝내긴 뭔가 아쉬우니까... 다음 글에서는 DANN 코드 리뷰를 해보도록 하겠다.
[ 참고 사이트 ]
https://arxiv.org/abs/1505.07818
Domain-Adversarial Training of Neural Networks
We introduce a new representation learning approach for domain adaptation, in which data at training and test time come from similar but different distributions. Our approach is directly inspired by the theory on domain adaptation suggesting that, for effe
arxiv.org
https://jamiekang.github.io/2017/06/05/domain-adversarial-training-of-neural-networks/
https://www.youtube.com/watch?v=n2J7giHrS-Y
http://dsba.korea.ac.kr/seminar/?mod=document&uid=1325
https://jayeon8282.tistory.com/7
http://jaejunyoo.blogspot.com/2017/01/domain-adversarial-training-of-neural.html
https://blog.lunit.io/2018/04/24/deep-supervised-domain-adaptation/



