Domain Adaptation의 한 부류인 Latent Feature Space Trasnformation에 대한 다섯번째 정리 글이다. 이번 글에서는 Domain-Adversarial training of Neural Networks 논문를 Keras로 직접 구현한 코드 리뷰 시간을 갖고자 한다. 이전에 혼자서 CycleGAN 구현했던 코드를 바탕으로 여러 Github 참고하면서 작업을 진행했다. 먼저 이전 글에서 설명했던 그림을 다시 봐보면서 구현 시 고려해야할 점들을 짚어보자.
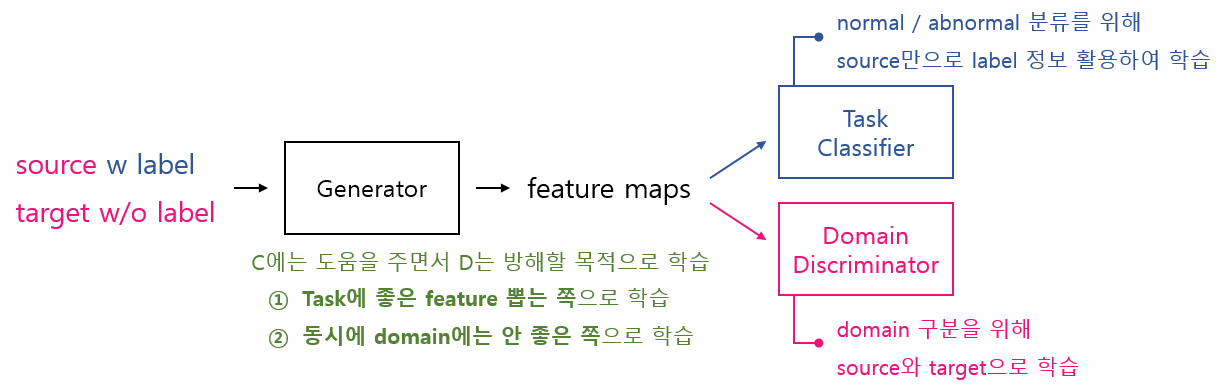
- Inputa Data를 Source와 Target으로 구성하면서 어떻게 Task Classifier는 Source만으로 학습하게 만들지??
- 어떻게 하면 Generator가 Domain 특성은 뭉개면서 Task에는 좋은 Feature를 뽑도록 학습시킬 수 있지??
- 어떻게 하면 Generator와 Domain Discriminator를 경쟁적으로 학습시킬 수 있지??
항상 느끼지만 논문의 핵심 아이디어를 이해하는 건 어렵다. 근데 이를 코드로 옮겨서 구현하는 건 더 어려운 작업인 것 같다. 특히 객체 인식의 경우엔... 정말로 Google과 Github가 없던 시절에는 어떻게 살았을까 싶을 정도다. 아무튼 이제 DANN을 어떤 식으로 구현했는지 살펴보도록 하자.
1. Input Data 구성
DANN 학습을 위해 Epoch마다 Source와 Target으로 구성된 데이터를 생성하여 모델의 학습 데이터로 사용한다. 그리고 Task Classifier, Generator, Domain Discriminator에 요구되는 Label의 형태가 다르기 때문에 Epoch마다 각 SubNet에 맞게 생성하여 정답 데이터로 사용한다. 따라서 학습에 사용되는 최종적인 Input Data의 형태는 아래 그림과 같다.
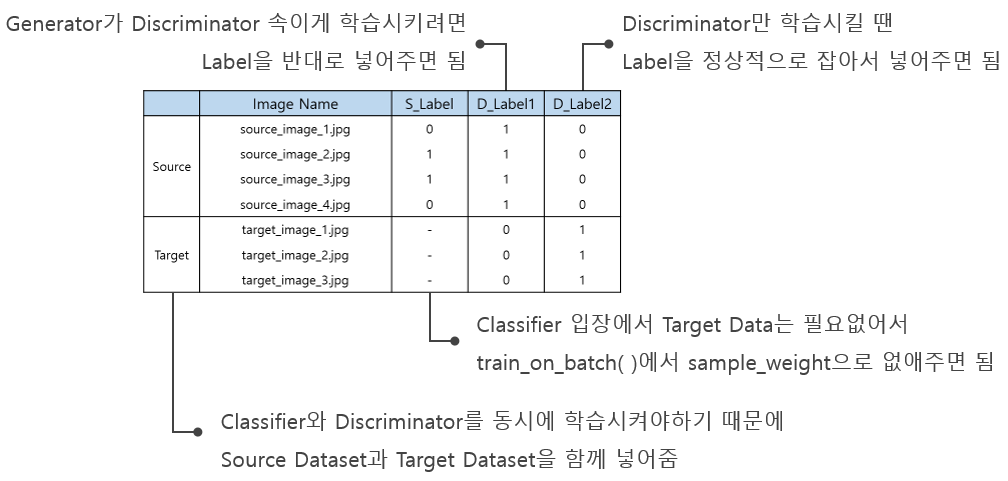
- S_Label = Source Label = Label for Task Classifier
D_Label1 = Domain Label 1 = Label for Generator
D_Label2 = Domain Label 2 = Label for Domain Discriminator - Generator가 Domain 특성은 뭉개면서 Task에는 좋은 Feature를 뽑도록 학습시키려면 Source와 Target을 같이 넣어줘야 한다. 목표하는 Feature를 뽑으려면 두 데이터셋를 함께 봐야지만 가능하기 때문이다.
- Generator가 Domain 특성을 뭉갠다는 말은 Domain Discriminator를 속인다는 뜻이다. 즉, Domain Discriminator가 Source는 Target으로 Target은 Source로 인식하도록 Feature를 뽑아야한다. 그러려면 Label 자체를 Generator에게 반대로 줘서 학습시키면 된다. 이는 일반적인 GAN에서 사용하는 방식과 같다.
- Domain Discriminator는 Source는 Source로 Target은 Target으로 판별하도록 학습되어야하기 때문에 Label을 정상적으로 잡아주면 된다.
- train_on_batch( )의 sample_weight arg를 통해서 Target에 의해 계산된 Loss가 Task Classifier에 영향을 주지 않도록 설정한다.
2. train_on_batch( )의 sample weight 활용
보통 Keras로 GAN 모델을 짤 때 학습에는 fit( )이나 fit_generator( ) 함수 말고 train_on_batch( )를 사용한다. train_on_batch( )를 사용하면 Tensorflow에서 sess.run( )을 통해 optimization을 하는 것과 비슷하게 batch data로 직접 네트워크를 번갈아가며 학습 시킬 수 있기 때문이다. 그리고 train_on_batch( )의 sample_weight이라는 argument를 사용하면 Task Classifier에는 불필요한 Target Dataset Loss를 없애줄 수 있다. 아래 그림을 같이 봐보자.
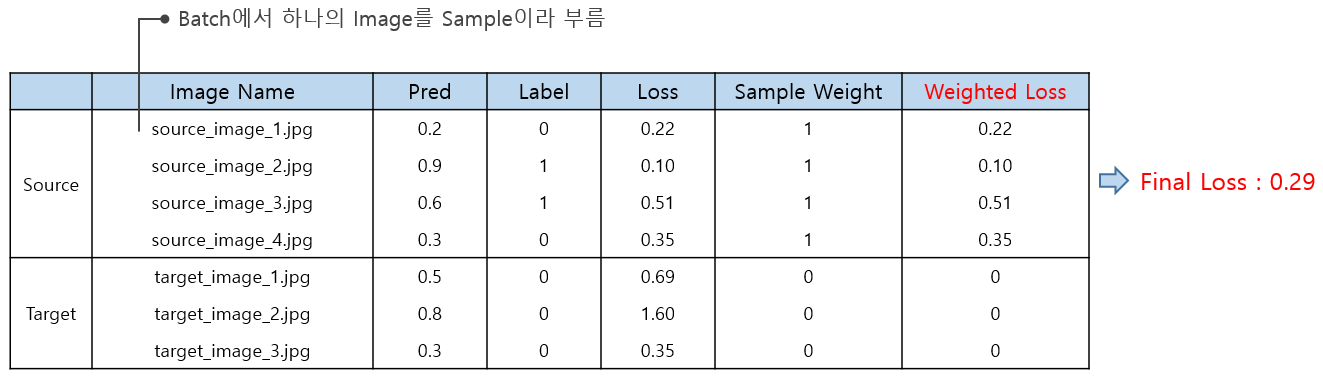
- Input으로 Source와 Target을 같이 넣는 이상
Task Classifier는 Target Dataset에 대해서도 Loss를 계산할 수 밖에 없다. - Target Dataset의 Label 정보를 실제로 모른다해서 코딩할 때도 Null 값을 넣어줄 순 없으니
실제 코드에서는 "0"으로 채워서 넣으면 된다. 어떤 값으로든 채워져야 에러가 안 난다. - 만약 Task Classifier의 Loss Function이 Binary Crossentropy이라면,
Loss는 Source와 Target 모두에서 Loss 열과 같이 계산된다. - 이때 Target에 의한 loss가 Task Classifier의 Weight 업데이트에 사용되어서는 안 된다.
이를 위해 train_on_batch( )의 sample_weight arg를 사용해야 한다.
Sample Weight 열처럼 값을 Target인 부분에만 "0"으로 설정해서 train_on_batch( )에 넘겨주면
Target sample로도 Loss 계산이 진행 되었더라도 "0"이 곱해지기 때문에 Final Loss에 영향을 주지 않는다.
3. 코드 리뷰 1차
이쯤에서 Input Data와 sample_weight에 들어갈 Label Array를 구성하고 최종적으로 train_on_batch( )를 사용해서 학습을 시키는 코드 부분을 같이 살펴보자.
combined_train_x = np.vstack((source_train_x, target_train_x))
task_train_y = np.vstack((source_train_y, np.zeros_like(source_train_y)))
tmp_batch_size = len(source_train_x)
domain_y_1 = to_categorical(np.array(([1] * tmp_batch_size + [0] * tmp_batch_size)))
domain_y_2 = to_categorical(np.array(([0] * tmp_batch_size + [1] * tmp_batch_size)))
sample_weights_task = np.array(([1] * tmp_batch_size + [0] * tmp_batch_size))
sample_weights_domain = np.ones((tmp_batch_size * 2,))
loss1 = combined_network.train_on_batch(
x = combined_train_x,
y = [task_train_y, domain_y_1],
sample_weight = [sample_weights_task, sample_weights_domain])- [Line 1]
Source와 Target을 엮어서 Input Data 만듦 - [Line 2]
Task Classifier를 위한 Source Label 생성 - [Line 4~6]
Generator와 Domain Discriminator 학습을 위한 Label 따로 생성 - [Line 8, 9]
Task Classifier 용 sample_weight과 Domain Discriminator 용 sample_weight 생성
(1) sample_weights_task는 위의 그림처럼
Source Dataset에는 "1", Target Dataset에는 "0"이 들어가도록 설정
(2) sample_weights_domain는 Domain Discriminator에 붙는 정보로
모든 데이터를 사용해줘야하기 때문에 전부 "1"이 되도록 설정 - [Lin 11~14]
combined_network는
Generator뒤에 Task Classifier와 Domain Discriminator가 붙은 구조로 2개의 Output을 뽑음
따라서 y에는 [task_train_y, domain_y_1],
sample_weight에는 [sample_weights_task, sample_weights_domain]를 넣어줘서
각각 Task Classifier와 Domain Discriminator에 연결되도록 해줘야함
! 이쯤에서 광고 보고 넘어가자 !

4. Generator와 Discriminator 경쟁적으로 학습
데이터셋에 대한 설명은 끝났으니 이제 Generator, Task Classifier, Domain Discriminator를 어떻게 유기적으로 학습시키는 지에 대해 알아보자. 단순히 Classification 문제로 접근했다면 Generator와 Task Classifier만 연결해서 학습시키면 되지만, DANN에서는 Domain Discriminator를 보조자 역할로서 Generator와 경쟁적으로 학습시켜야한다. 아래 그림을 봐보자.

- 먼저 Generator와 Task Classifier를 Input image / S_Label / D_Label1을 사용하여 학습시킨다.
Generator는 Domain 특성은 뭉개면서 Task Classifier에는 좋은 Feature를 뽑으려고 노력한다. - 그 다음으로 Domain Discriminator만 학습시킨다.
Generator가 안 좋은 Feature를 뽑는다해도 Domain 판별을 잘하려고 노력한다. - Epoch 마다 (Step 1) Generator, Task Classifier 학습 / (Step 2) Domain Discriminator 학습의 흐름을 반복한다.
- 이런 흐름으로 코드 작업을 진행하려면
(1) Generator와 Task Classifier, Domain Discriminator가 연결된 combined_network와
(2) Generator와 Domain Discriminator가 연결된 stacked_discriminator를 준비해야하고
(3) 각 Step의 상황에 맞게 Network의 Trainable 속성을 False로 잡아줘야한다.
5. 코드 리뷰 2차
먼저 combine_network와 stacked_discriminator를 준비하는 부분을 봐보자.
## build combined network for task classification and domain-adaptation adversarial training
subnet_discriminator.trainable = False
combined_network = self.combine_networks(feature_extractor, [subnet_classifier, subnet_discriminator])
combined_network.compile(
optimizer = self.opti,
loss = {
'subnet_classifier' : 'categorical_crossentropy',
'subnet_discriminator' : 'categorical_crossentropy'},
loss_weights = {
'subnet_classifier' : self.cls_weight,
'subnet_discriminator' : self.disc_weight},
metrics = ['accuracy']
)
subnet_discriminator.trainable = True
## build stacked disciminator for domain-adaptation adversarial training
feature_extractor.trainable = False
stacked_disciminator = self.combine_networks(feature_extractor, [subnet_discriminator])
stacked_disciminator.compile(
optimizer = self.opti,
loss = 'categorical_crossentropy',
metrics = ['accuracy']
)
feature_extractor.trainable = True- [Line 2, 14]와 [Line 17, 24]를 보면 trainable 속성을 False로 둔 다음 compile하고 다시 True로 설정하는 것을 볼 수 있다.
- (Step 1)에서는 Generator와 Task Classifier만 학습시키고,
(Step 2)에서는 Domain Discriminator만 학습시키기 위함이다.
compile 전에 trainable = False로 잡는 건 GAN 구현할 때 주로 쓰이는 방법이다.
'compile할 때 학습할 가중치 정보들을 가져오는데 이때 trainable = True인 가중치들만 가져와서 이렇게 설정하는 거다' 정도로 이해하면 되는 것 같다.
다음으로 combined_network와 stacked_discriminator를 번갈아가며 학습시키는 부분에 대해 봐보자.
for epoch in range(epochs):
~~~
loss1 = combined_network.train_on_batch(
x = combined_train_x,
y = [task_train_y, domain_y_1],
sample_weight = [sample_weights_task, sample_weights_domain]
)
loss2 = stacked_disciminator.train_on_batch(combined_train_x, [domain_y_2])
~~~- fit( )이나 fit_generator( ) 사용하는 게 아니고 train_on_batch( )를 사용하기 때문에 크게 복잡한 건 없다.
- Epoch 마다 combined_network 먼저 학습 시키고나서 stacked_discriminator를 학습시켜주면 된다.
전체 코드는 좀 더 정리하고 Github에 올릴 예정이다.
[ 참고 사이트 ]
https://github.com/sghoshjr/Domain-Adversarial-Neural-Network
GitHub - sghoshjr/Domain-Adversarial-Neural-Network: Implementation of Domain Adversarial Neural Network in Tensorflow
Implementation of Domain Adversarial Neural Network in Tensorflow - GitHub - sghoshjr/Domain-Adversarial-Neural-Network: Implementation of Domain Adversarial Neural Network in Tensorflow
github.com
https://github.com/pumpikano/tf-dann
https://github.com/sjchoi86/advanced-tensorflow/tree/master/dann
https://github.com/S-Choudhuri/Adversarial-Domain-Adaptation-with-Keras
https://github.com/ssamot/DANN-keras



